

Американские разработчики представили нейросетевую модель Speech2Face. Обученная на нескольких миллионах видео, эта модель умеет воссоздавать по спектрограмме речи человека примерное изображение его лица, основываясь на трех основных параметрах: поле, расе и возрасте. Описание алгоритма и результаты его работы доступны в препринте, опубликованном на arXiv.org.
На фото выше: Реальные изображения людей, восстановленные изображения и изображения, сделанные на основе голоса
Ученые из Массачусетского технологического института при участии Тэхёна О (Tae-Hyun Oh) решили проверить, можно ли точно восстановить внешность человека по его голосу с помощью машинного обучения. Для обучения нейросети они использовали датасет AVSpeech, состоящий из более миллиона коротких видео более ста тысяч разных людей: каждое видео в базе данных разделено на аудио- и видеодорожку. Архитектура натренированной нейросети устроена следующим образом. Сначала предварительно натренированный алгоритм VGG-Face (ранее его использовали для создания модели, которая умеет определять сексуальную ориентацию человека — при условии ее бинарности) использует особенности лица человека из кадра на видео для создания изображения лица человека в анфас с нейтральным выражением лица. Другая часть алгоритма воссоздает из аудиодорожки использованного видео (небольшого фрагмента — от 3 до 6 секунд) спектрограмму речи и, используя результаты из параллельной нейросети, генерирующей изображение лица, дает на выход примерное изображение лица человека, который разговаривает на видео.
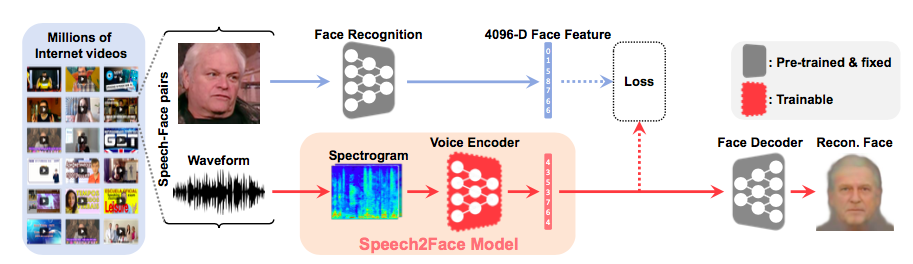
Схема работы алгоритма
Точность разработанного алгоритма оценили по трем демографическим показателям: ученые сравнили пол, примерный возраст и расу оригинального изображения человека из видео и изображения, восстановленного на основе голоса. Несмотря на то, что авторам удалось добиться успехов в восстановлении изображений некоторых людей по видео, объективные метрики показывают несовершенство разработанной модели. В частности, модель хорошо угадывает пол человека, но редко может определить возраст с точностью до десяти лет, а также лучше всего «рисует» людей с европеоидной и азиатской внешностью. Последнее разработчики объясняют неравномерным распределением рас в обучающей выборке.
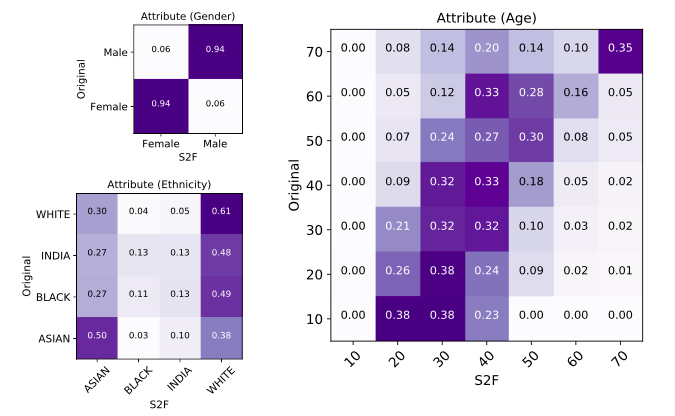
Матрица ошибок для пола, расы и возраста. Чем контрастнее цвет по диагонали, тем точнее определен параметр
Исследователи отметили, что целью их работы не было точное восстановление внешности человека по его голосу; сосредоточились они именно на выделении и точности некоторых важных параметров: пола, возраста и этнической принадлежности. Именно поэтому точно показать по голосу, как выглядит человек, пока что нельзя: при этом определенных параметров хватит для того, чтобы создавать, к примеру, анимационные аватары человека по его голосу. Также ученые отмечают, что их работа носит также исследовательскую пользу: генерация целых лиц на основе голоса поможет лучше изучить корреляцию с внешностью.
На прошлой неделе другой алгоритм, который выделяет особенности лица из изображения человека, использовали для того, чтобы превратить статичные изображения (не только фотографии, но и картины) в анимированные изображения.
Оригинал earth-chronicles.ru
